
장단기 기억 네트워크(LSTM) 및 GRU 개념 완벽 정리
여러분, RNN이 오래된 기억을 잘 잊어버린다는 사실, 알고 계셨나요?
그래서 LSTM과 GRU가 등장했답니다!
그 비밀을 지금부터 풀어볼게요 😊
안녕하세요, 여러분!
오늘은 딥러닝에서 시계열 데이터나 자연어 처리에 자주 등장하는 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)에 대해 쉽고 재밌게 풀어보려 합니다. RNN이 가지는 한계를 어떻게 극복했는지, 왜 이 두 모델이 현대 딥러닝의 필수 요소로 자리 잡았는지 함께 알아봐요. 그리고 Orange Data Mining으로 직접 실습해보며 그 원리를 눈으로 확인해보는 시간도 준비했으니 끝까지 집중해주세요!
목차
1. RNN의 한계와 LSTM/GRU 등장 배경
RNN(Recurrent Neural Network)은 순차적 데이터를 처리하는 데 최적화된 신경망입니다. 시계열 데이터나 자연어 처리에서 등장하는 이 모델은, 이전 시점의 정보를 다음 시점으로 전달하며 시간의 흐름을 반영하는 데 탁월한 구조를 가지고 있어요. 하지만, 여기에도 중대한 약점이 숨어 있습니다.
🔍 RNN이 겪는 문제: 장기 의존성 문제
문장이 길어지면 앞부분 정보를 잘 기억하지 못하는 문제가 발생합니다. 예를 들어, "나는 오늘 아침에 커피를 마셨다. 그리고 점심엔..." 같은 문장을 처리할 때, '커피'라는 정보는 시간이 지나면서 잊혀져버릴 수 있어요.
이런 현상은 기울기 소실(Vanishing Gradient) 문제 때문인데요. 역전파 학습 과정에서 시점이 멀어질수록 정보가 희미해져서, 결국 학습이 어려워지는 거죠.
🚀 그래서 등장한 LSTM과 GRU
이 문제를 해결하기 위해 등장한 게 바로 LSTM(Long Short-Term Memory)와 GRU(Gated Recurrent Unit)입니다. 이 두 모델은 기억을 선택적으로 유지하거나 버리는 구조를 가지고 있어요. 덕분에 긴 문장이나 오랜 시간의 데이터에서도 중요한 정보를 오래 기억할 수 있게 됐죠.
쉽게 말해, 필요한 정보는 챙기고, 필요 없는 건 과감히 버리는 ‘기억 관리 시스템’을 갖춘 RNN의 업그레이드 버전인 셈입니다. 😎
- 장기 의존성 문제로 인해 앞선 정보의 전달이 어려움
- 기울기 소실/폭주 현상으로 학습이 불안정해짐
- 문장이 길어질수록 의미 맥락을 유지하기 어려움
| 구분 | RNN | LSTM/GRU |
|---|---|---|
| 장기 의존성 | 취약함 | 강함 (Gate 구조로 보완) |
| 구조 | 단순 | 복잡 (Gate 포함) |
| 학습 안정성 | 낮음 (Gradient 문제) | 높음 |
이제 LSTM과 GRU가 왜 필요했는지 조금 감이 오시죠? 다음 챕터에서는 LSTM의 구조와 작동 원리를 조금 더 구체적으로 들여다볼게요!
2. LSTM의 구조와 동작 원리 🔄
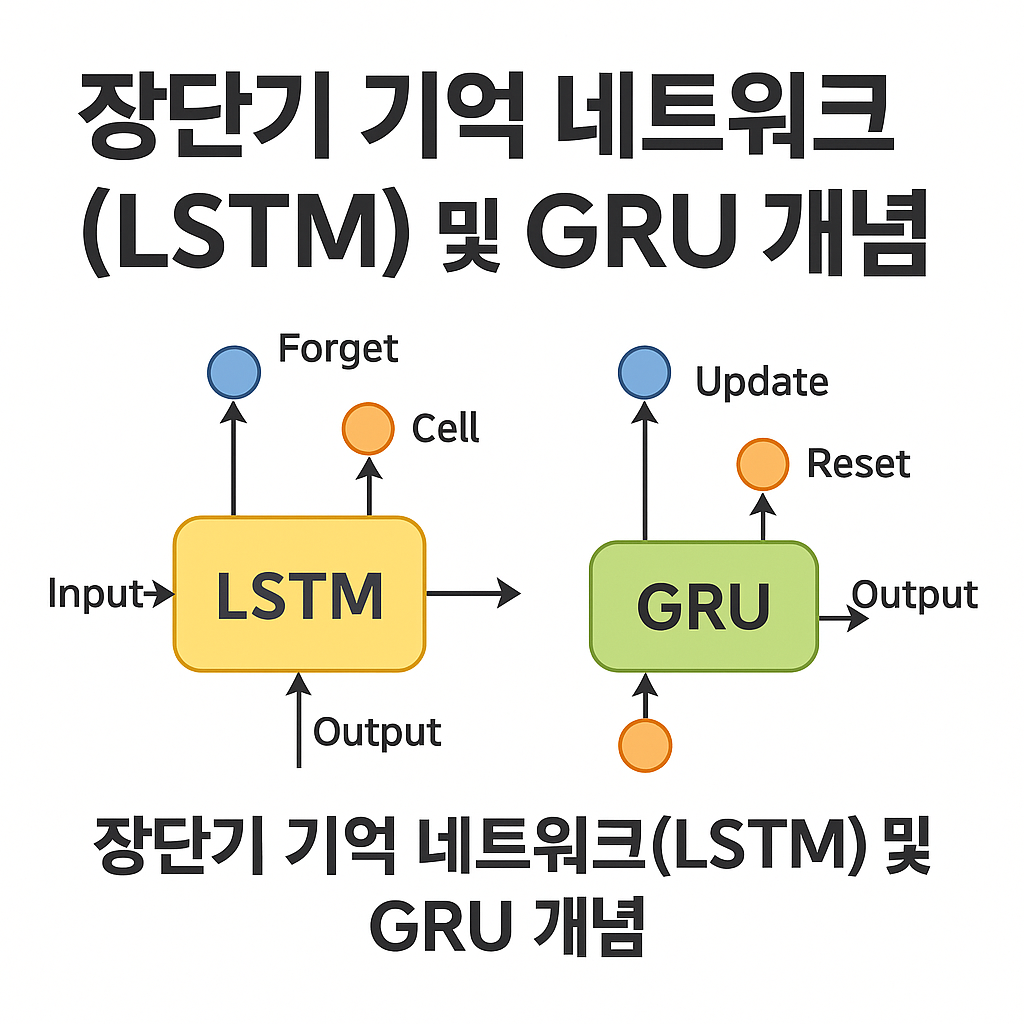
LSTM(Long Short-Term Memory)은 일반 RNN의 한계를 극복하기 위해 고안된 모델이에요. 핵심은 셀 상태(Cell State)라는 개념과 정보를 조절하는 게이트(Gate) 구조에 있습니다. 이 게이트들 덕분에 LSTM은 장기적인 정보도 오랫동안 보존할 수 있죠.
🧠 LSTM의 3가지 핵심 게이트
- 입력 게이트(Input Gate): 현재 입력 정보를 얼마나 기억할지 결정
- 망각 게이트(Forget Gate): 과거 정보를 얼마나 잊을지 결정
- 출력 게이트(Output Gate): 어떤 정보를 다음 셀로 보낼지 결정
🧬 셀 상태(Cell State): 기억의 고속도로
이 셀 상태는 일종의 기억 저장소로, 시간의 흐름에 따라 정보를 전달하면서도 필요에 따라 새로운 정보를 더하거나 기존 정보를 지울 수 있어요. 마치 고속도로 위에 정보가 실린 차들이 다니는 것처럼, 셀 상태는 중요한 정보만 실어 다음 셀로 넘기죠.
💡 흐름을 정리하면...
- 1. 망각 게이트가 셀 상태에서 버릴 정보를 골라내요.
- 2. 입력 게이트가 새로운 정보를 받아들이고 업데이트할지를 결정해요.
- 3. 셀 상태가 업데이트되고, 출력 게이트가 출력 값을 만들어내요.
📊 간단한 예시로 감 잡기!
문장 "나는 아침에 커피를 마셨다"를 처리한다고 가정해볼게요. 초기에는 ‘나는’, ‘아침에’ 같은 단어가 입력됩니다. LSTM은 이 정보를 입력 게이트로 기억할지 판단하고, 과거의 ‘커피’에 대한 기억이 있다면 망각 게이트에서 유지할지 말지를 판단하죠. 그 다음엔 ‘마셨다’라는 단어가 등장하면서, ‘무엇을 마셨는가?’를 기억한 셀 상태 덕분에 자연스럽게 ‘커피’라는 맥락을 유지할 수 있게 되는 거예요.
즉, LSTM은 단순 반복 구조가 아니라 스마트한 필터링 시스템을 탑재한 셀이라 보면 됩니다!
3. GRU의 구조와 특징 ✨
GRU(Gated Recurrent Unit)는 LSTM과 비슷하지만 구조가 더 간단하면서도 효율적이에요. LSTM이 가진 게이트 구조에서 몇 가지를 통합해 빠른 학습과 적은 파라미터로도 좋은 성능을 낼 수 있도록 만들어졌죠.
🧩 GRU의 구성 요소
- 리셋 게이트(Reset Gate): 과거 정보를 얼마나 무시할지 결정해요.
- 업데이트 게이트(Update Gate): 기억을 얼마나 유지할지 판단해요.
GRU는 셀 상태와 은닉 상태가 통합되어 하나의 상태로 작동해요. 덕분에 구조가 LSTM보다 더 간단하고 계산량도 적어요. 그러면서도 성능은 거의 비슷하다는 게 큰 장점이죠.
📈 GRU 동작 순서
- 1. 업데이트 게이트가 과거 정보를 얼마나 유지할지 정해요.
- 2. 리셋 게이트가 이전 상태를 어느 정도 무시할지 조절해요.
- 3. 이 두 게이트를 활용해 새로운 상태를 생성하고, 이를 다음 단계로 전달해요.
⚖️ LSTM과 GRU의 가장 큰 차이
| 항목 | LSTM | GRU |
|---|---|---|
| 게이트 수 | 3개 (입력, 망각, 출력) | 2개 (업데이트, 리셋) |
| 상태 구조 | 셀 상태 + 은닉 상태 | 은닉 상태만 존재 |
| 계산 비용 | 조금 더 무거움 | 더 가볍고 빠름 |
요약하자면, GRU는 계산이 가벼운 대신 구조가 단순하고, LSTM은 조금 더 복잡하지만 세밀한 기억 조절이 가능하다는 차이가 있어요. 상황에 따라 골라 쓰는 센스가 필요하겠죠? 😉
4. LSTM vs GRU 비교 분석 ⚔️
LSTM과 GRU, 두 모델은 구조도 다르고 성격도 다릅니다. 그렇다면 어떤 상황에서 어떤 모델을 선택해야 할까요? 여기서는 성능, 구조, 학습 속도, 실제 적용 분야 등 다양한 측면에서 이 둘을 비교해볼게요.
🔬 LSTM과 GRU, 어떤 점이 어떻게 다를까?
| 비교 항목 | LSTM | GRU |
|---|---|---|
| 구조 | 복잡 (3개 게이트 + 셀 상태) | 간단 (2개 게이트, 셀 상태 없음) |
| 학습 속도 | 느림 | 빠름 |
| 모델 파라미터 수 | 많음 | 적음 |
| 기억 유지 능력 | 장기 기억에 더 강함 | 단기 + 중기 기억에 적합 |
| 응용 예시 | 언어 번역, 복잡한 자연어 처리 | 실시간 예측, 감성 분석, 음성 인식 |
💡 선택 기준 요약
- 속도와 자원 효율성이 중요하다면 → GRU
- 긴 문맥을 유지해야 한다면 → LSTM
- 구현 단순화가 필요하다면 → GRU
실제로는 데이터를 여러 모델에 넣어보고 비교해보는 게 가장 확실해요. LSTM이든 GRU든, 현실 데이터에 얼마나 잘 맞느냐가 진짜 핵심이거든요!
그럼 이제 Orange Data Mining에서 이 구조들을 어떻게 활용할 수 있는지, 실습으로 함께 알아볼까요? ✨
5. Orange Data Mining으로 LSTM 실습 💻
LSTM과 GRU의 구조와 원리를 이해했으니, 이제는 직접 써봐야죠? Orange Data Mining은 시각화 기반의 머신러닝 툴로, 코딩 없이도 딥러닝 구조의 원리를 실습해볼 수 있어요. 현재 Orange는 기본적으로 LSTM이나 GRU를 직접 구현하진 않지만, Neural Network 위젯을 이용해 유사한 MLP 실습이 가능합니다. 그리고 Python Script 위젯을 활용하면 간단한 LSTM 코드를 삽입할 수도 있어요!
🔧 Orange에서 LSTM 실습하기 위한 2가지 방법
- 1. MLP 구조로 유사한 딥러닝 실습 진행:
Orange의 Neural Network 위젯을 사용해 은닉층을 여러 개 쌓고 ReLU 등 활성 함수를 조정해보세요. - 2. Python Script 위젯 활용:
LSTM을 직접 구현하고 싶다면 Keras를 불러와 간단한 LSTM 모델을 만들어보는 것도 가능해요.
👨💻 실습 예시: 시계열 데이터 예측용 LSTM
아래는 Keras를 이용한 간단한 LSTM 예시 코드입니다. Orange에서 Python Script 위젯을 통해 이 코드를 실행할 수 있어요.
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
# 예제 데이터 (단순 sine 파형)
x = np.linspace(0, 100, 500)
X = np.array([np.sin(x[i:i+10]) for i in range(490)])
Y = np.array([np.sin(x[i+10]) for i in range(490)])
X = X.reshape((X.shape[0], X.shape[1], 1))
# LSTM 모델 생성
model = Sequential()
model.add(LSTM(50, input_shape=(10, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.fit(X, Y, epochs=20, verbose=1)
이렇게 Orange + Keras 조합으로 LSTM을 실습해보면, 구조와 원리를 이해하는 데 큰 도움이 됩니다. 시계열 예측, 텍스트 생성 등 다양한 분야에 쉽게 확장할 수 있어요!
📌 실습 팁
- 시계열 데이터를 준비할 때는 슬라이딩 윈도우 방식으로 입력 시퀀스를 구성해요.
- 모델 학습 전에 정규화 또는 표준화를 꼭 해주는 게 좋아요!
- 에폭 수와 LSTM 노드 수는 실험적으로 조절하면서 최적값을 찾아가세요.
이제 GRU도 비슷하게 Python Script로 구성할 수 있어요. 다음 단계에서 실제 현업에서는 어떻게 쓰이는지, 어떤 분야에 적합한지 알아보겠습니다!
6. 실전 응용 사례 및 확장 방향 🚀
LSTM과 GRU는 단순히 이론적인 개념에 그치지 않아요. 오늘날 우리가 사용하는 많은 AI 기술의 핵심에 자리하고 있죠. 지금부터는 실제로 이 두 구조가 어떻게 활용되고 있는지, 그리고 어떤 방향으로 확장되고 있는지를 알아볼게요.
🌍 다양한 응용 사례
- 자연어 처리: 기계 번역, 문장 생성, 감성 분석 등에서 LSTM과 GRU가 중심 역할을 해요.
- 음성 인식: 시간에 따라 변화하는 음성 데이터를 분석해 텍스트로 변환하는 데 주로 사용돼요.
- 시계열 예측: 주식 가격 예측, 날씨 예측, 센서 데이터 예측 등에 활용됩니다.
📈 LSTM과 GRU의 한계와 발전 방향
물론 LSTM과 GRU도 완벽하진 않아요. 병렬 처리에 약하고 긴 문장에서는 여전히 한계가 있죠. 이런 점을 보완하기 위해 나온 모델이 바로 Transformer예요. 요즘 핫한 GPT, BERT 모델들도 이 구조를 기반으로 하고 있답니다.
💬 그래서 언제 LSTM/GRU를 써야 할까?
- 데이터가 시간 순서에 민감하고 비교적 짧은 문맥이라면 여전히 LSTM/GRU가 최적이에요!
- Transformer가 무거운 환경이나 실시간 처리에는 GRU가 훨씬 가볍고 유리할 수도 있어요.
이처럼 LSTM과 GRU는 지금도 많은 분야에서 활약 중이에요. 특히 Orange와 같은 도구를 활용하면 쉽게 실습하고, 학습 데이터를 시각화해가며 배울 수 있으니 더욱 좋죠!
이제 여러분도 LSTM과 GRU의 구조적 차이, 실전 활용법, 선택 기준까지 완벽히 이해하게 되셨을 거예요. 마지막으로, 오늘 배운 내용을 정리하면서 어떤 식으로 활용할 수 있을지 마무리해볼게요.
🧾 마무리하며: LSTM과 GRU, 당신의 선택은?
오늘은 LSTM과 GRU라는 두 강력한 순환 신경망 구조에 대해 살펴보았습니다. RNN의 한계를 극복하며 등장한 이 두 구조는 각각의 장단점을 가지고 있으며, 다양한 상황에 맞게 현명하게 선택하는 것이 중요하죠.
LSTM은 장기 의존성 문제 해결에 강하고, 복잡한 문맥을 다루는 데 효과적이며, GRU는 구조가 간단하고 학습 속도가 빨라 실시간 처리에 적합해요. 또한 Orange를 통해 이런 이론을 실제로 실습하고, 시각적으로 확인할 수 있다는 점도 학습 효과를 배가시켜줍니다!
머신러닝을 처음 접하는 여러분도, 어렵지 않게 RNN의 고급 구조를 이해하고 실습할 수 있어요. 이제 실제 프로젝트에 LSTM 또는 GRU를 도입해보는 건 어떠신가요? 🚀
다음 글에서는 자연어 처리(NLP)의 개요와 대표적인 활용 사례들에 대해 알아볼 예정이에요. 텍스트 분석, 챗봇, 번역 시스템의 뒷이야기가 궁금하셨다면 꼭 기대해 주세요!
'OrangeDataMining' 카테고리의 다른 글
| 단어 임베딩(Word Embedding)과 Word2Vec, 자연어 이해의 시작점 (0) | 2025.05.07 |
|---|---|
| 자연어 처리(NLP) 개요 및 활용 사례 (2) | 2025.05.07 |
| 시계열 데이터(Time-Series Data) 개념 완전정복 (0) | 2025.05.06 |
| 순환 신경망(RNN) 개요 및 활용 (1) | 2025.05.06 |
| 전이 학습(Transfer Learning) 개념 및 활용 (1) | 2025.05.05 |



