
딥러닝과 전통적 머신러닝의 차이
“왜 요즘엔 다들 머신러닝 말고 딥러닝만 이야기하는 걸까?”
이런 질문, 한 번쯤 해보셨죠?
알고 보면 둘 다 인공지능의 일종이지만, 엄청난 차이가 있답니다.
안녕하세요!
오늘은 우리가 일상에서 자주 듣게 되는 "머신러닝"과 "딥러닝"의 본질적인 차이에 대해 이야기해보려고 합니다. "둘 다 AI라면서 뭐가 다른 거지?"라는 궁금증을 가진 분들께 이 글이 눈이 번쩍 뜨이는 시작점이 되었으면 해요. 딥러닝이라는 이름에 걸맞게, 조금 더 ‘깊이’ 파고들되, 초보자도 쉽게 이해할 수 있도록 비유와 사례를 곁들여서 설명드릴게요. Orange Data Mining 툴을 통해 실습까지 연동되는 실제적인 흐름으로 안내해드릴 예정이니, 끝까지 집중해 주세요 😊
목차
1. 전통적 머신러닝이란 무엇인가요?
딥러닝을 이야기하기 전에 먼저 전통적인 머신러닝(Machine Learning)이 뭔지부터 정리해볼게요. 우리가 흔히 말하는 머신러닝은 컴퓨터가 데이터를 통해 규칙을 스스로 학습해서 예측이나 분류 같은 작업을 하게 만드는 기술이에요.
📚 전통적인 머신러닝의 대표 알고리즘
- 선형 회귀 (Linear Regression): 연속적인 값을 예측할 때 사용돼요. 예: 광고비에 따른 매출 예측
- 로지스틱 회귀 (Logistic Regression): 이진 분류에 많이 쓰여요. 예: 이메일이 스팸인지 아닌지
- 결정트리 (Decision Tree): 규칙 기반의 트리 구조로 분류를 진행해요.
- K-최근접 이웃 (KNN): 가장 가까운 데이터 포인트들을 참조해 분류해요.
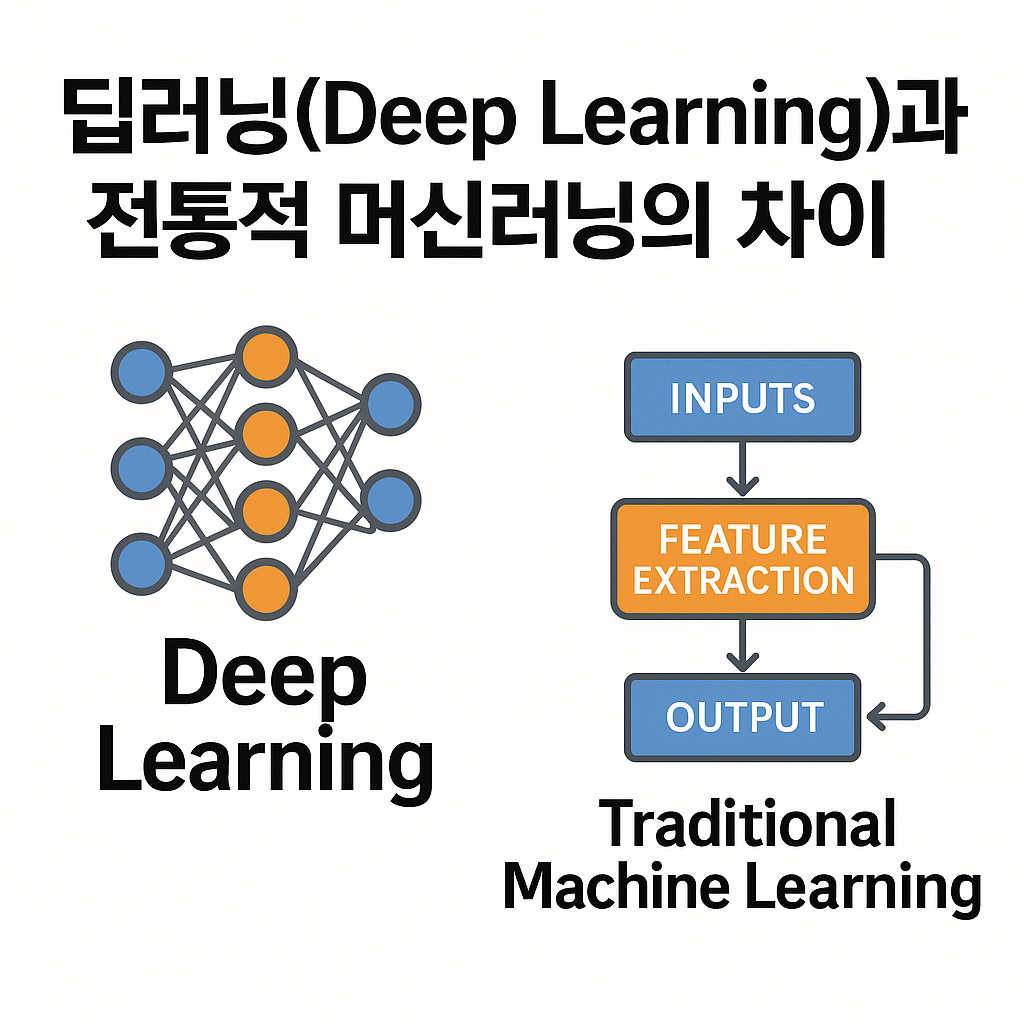
이 모든 전통적 머신러닝 알고리즘들의 공통점은 특징(feature)을 사람이 직접 추출한다는 점이에요. 예를 들어 이미지를 분류하려면, "색상", "모서리", "모양" 같은 속성을 사람이 먼저 설계해야 하죠. 이걸 수동 피처 엔지니어링이라고 불러요.
🧪 Orange Data Mining에서의 실습 예시
Orange에서는 전통적인 머신러닝을 아주 쉽게 실습할 수 있어요. 예를 들어 Iris 데이터셋을 불러와서 Logistic Regression, Decision Tree 등을 연결해 모델을 학습시키고, Test & Score 위젯으로 정확도를 비교해볼 수 있죠. 또한 Scatter Plot으로 각 모델이 어떤 방식으로 데이터를 분리하는지도 시각적으로 확인할 수 있어요.
| 알고리즘 | 용도 | Orange 위젯 |
|---|---|---|
| Linear Regression | 연속형 예측 | Linear Regression |
| Logistic Regression | 이진 분류 | Logistic Regression |
| Decision Tree | 복잡한 규칙 기반 분류 | Tree |
정리하자면, 전통적 머신러닝은 사람이 중심이 되는 특징 추출을 기반으로 모델을 학습시키는 구조예요. 정형 데이터(숫자, 표 등)에는 아주 강력하지만, 이미지나 음성처럼 복잡한 비정형 데이터에는 조금 약할 수 있어요.
2. 딥러닝은 왜 ‘Deep’할까요?
딥러닝이라는 말, 요즘 정말 많이 들어보셨죠? 근데 여기서 ‘딥(Deep)’이라는 말은 도대체 뭘 의미할까요? 단순히 똑똑하다, 더 잘난 AI란 뜻은 아니에요. 여기서의 ‘딥’은 신경망의 층(Layer)이 깊다는 뜻이에요.
🧠 인공신경망(Artificial Neural Network)의 핵심
딥러닝은 사람 뇌의 신경 구조를 본떠서 만든 인공신경망(ANN)을 기반으로 합니다. 이 신경망은 입력층 → 은닉층(여러 개) → 출력층으로 구성되어 있어요.
- 입력층 (Input Layer): 데이터가 처음 들어오는 곳입니다.
- 은닉층 (Hidden Layer): 이곳에서 데이터가 변형되고 패턴을 학습합니다. 층이 많을수록 ‘딥’합니다!
- 출력층 (Output Layer): 결과가 나오는 곳이죠.
머신러닝에서는 사람이 직접 특징을 뽑아줬다면, 딥러닝은 특징을 자동으로 추출합니다. 예를 들어 이미지 분류 문제에서, 사람이 “고양이는 귀가 뾰족하다”고 알려주지 않아도, 딥러닝은 그 패턴을 스스로 배워요. 이게 바로 딥러닝의 ‘진짜 힘’이에요!
🔧 Orange로 딥러닝 실습하면?
Orange에서는 Neural Network 위젯을 사용해서 간단한 딥러닝 모델을 시도할 수 있어요. Iris 데이터로 MLP(Multi-Layer Perceptron)를 적용하고, Test & Score로 모델 성능을 확인해보면 은닉층의 수에 따라 정확도가 어떻게 달라지는지도 바로 눈으로 확인할 수 있어요.
| 구성 요소 | 설명 | Orange 실습 위젯 |
|---|---|---|
| 입력층 | 데이터가 처음 입력되는 부분 | File 위젯 → Neural Network |
| 은닉층 | 데이터의 패턴을 학습하는 내부 층 | Neural Network (파라미터 조정 가능) |
| 출력층 | 분류나 예측 결과가 나오는 부분 | Confusion Matrix 또는 Scatter Plot |
결론적으로, 딥러닝은 복잡한 구조와 자동화된 특징 학습을 통해 머신러닝보다 훨씬 강력한 문제 해결 능력을 보여줍니다. 물론 학습에 시간과 자원이 더 많이 들어간다는 단점도 있죠.
3. 머신러닝 vs 딥러닝 핵심 비교
머신러닝과 딥러닝, 둘 다 데이터를 학습해서 예측하는 인공지능 기술이긴 하지만, 내부 구조와 작동 방식은 매우 달라요. 그래서 정리해봤습니다. 아래 비교표 하나면, 어떤 상황에 어떤 기술을 써야 할지 감이 오실 거예요!
| 항목 | 머신러닝 (ML) | 딥러닝 (DL) |
|---|---|---|
| 데이터 크기 | 소규모 데이터에 적합 | 대규모 데이터가 필요 |
| 특징 추출 | 사람이 직접 설계 (Feature Engineering) | 자동 추출 (Representation Learning) |
| 학습 속도 | 빠름 | 느림 (연산량 많음) |
| 복잡한 문제 처리 | 한계가 있음 | 복잡한 문제 해결에 강함 |
| 대표 알고리즘 | SVM, KNN, 결정트리 등 | CNN, RNN, GAN 등 |
| 활용 분야 | 숫자 예측, 분류, 간단한 패턴 분석 | 이미지, 음성, 자연어 처리 등 |
📝 한 문장 요약!
머신러닝은 사람이 알려주는 특징으로 학습하고, 딥러닝은 스스로 특징을 찾아내는 초능력자입니다!
🧪 Orange 실습 포인트 비교
- 머신러닝 모델은 다양한 알고리즘 위젯을 조합해서 빠르게 실험 가능해요 (Tree, Logistic Regression 등).
- 딥러닝은 Neural Network 위젯을 활용해서 비선형 문제에 도전 가능하고, 복잡한 패턴 인식까지 실습해볼 수 있어요.
어떤 기술을 선택할지는 여러분의 데이터 특성, 문제의 복잡도, 학습 자원에 따라 달라져요. 둘 중 뭐가 더 좋다기보다는, ‘어떤 상황에 적절하냐’가 더 중요하다는 점, 꼭 기억하세요!
4. 실생활 예시로 이해하는 차이점
이론으로 아무리 잘 설명해도 감이 안 오신다고요? 괜찮아요. 우리 주변의 실생활 예시를 통해 머신러닝과 딥러닝의 차이를 느껴봅시다! 직관적으로 이해할 수 있도록 여러 비유와 사례를 준비했어요 😊
👨🍳 예시 1: 요리 레시피 따라하기
머신러닝은 사람이 만들어준 요리법(레시피)을 그대로 따라하는 거예요. 재료를 얼마나 넣어야 하는지, 불은 어느 정도로 줄여야 하는지, 모든 게 정해져 있죠.
반면 딥러닝은 어떤가요? 재료만 주어지면 요리사가 스스로 최적의 조리법을 찾아내는 거예요. 때로는 새로운 맛을 발견하거나, 기존 요리를 더 업그레이드할 수도 있죠. 바로 이런 자율성이 딥러닝의 힘이에요.
📸 예시 2: 사진 인식 AI
머신러닝을 사용할 때는 고양이와 개를 구분하려면, 귀 모양, 꼬리 길이, 코 크기 같은 특징을 사람이 일일이 뽑아서 알려줘야 해요.
하지만 딥러닝은? 수천 장의 사진을 넣어주면, 그 안에서 공통된 패턴을 스스로 학습해서 “이건 고양이, 이건 개”라고 구분할 수 있게 돼요. 사람보다 더 미세한 차이까지 잡아낼 수 있죠!
🧡 Orange에서 체험하기
- Orange의
Image Analyticsadd-on을 사용하면, 간단한 이미지 분류도 딥러닝 기반으로 실습할 수 있어요. - 사전 학습된 모델을 활용해 자동으로 이미지의 특징을 추출하고 분류하는 데 사용되죠.
🚗 예시 3: 자율주행차 vs 내비게이션
전통적인 머신러닝은 마치 내비게이션처럼 사람이 경로를 결정해주는 구조예요. 최단거리, 우회도로 등 몇 가지 옵션만 고려하죠.
반면 딥러닝 기반의 자율주행차는 도로 상황, 보행자 움직임, 신호등 상태까지 모든 걸 스스로 판단하고 반응해요. ‘스스로 운전하는 자동차’가 바로 딥러닝의 대표 사례입니다.
이처럼, 우리가 일상에서 쓰는 다양한 기술들이 머신러닝과 딥러닝의 특성을 반영해서 발전해나가고 있어요. 두 기술이 어떻게 실생활에 녹아들었는지 감이 좀 오시죠? 😄
5. Orange로 직접 비교해보기 🧡
지금까지 머신러닝과 딥러닝의 차이를 이론과 예시로 알아봤다면, 이제 직접 눈으로 확인해볼 차례입니다! Orange Data Mining 툴을 활용하면 코드 한 줄 없이도 두 모델의 차이를 시각적으로 비교할 수 있어요. 시작해볼까요? 😎
🔍 실습 1: 머신러닝 모델 만들기
- Orange 실행 후 File 위젯으로 Iris 데이터셋을 불러옵니다.
- Data Table 위젯을 연결하여 데이터를 확인합니다.
- Logistic Regression 또는 Tree 위젯을 연결해 모델을 만듭니다.
- Test & Score로 성능을 평가합니다 (정확도 확인 가능).
이 실습은 머신러닝 모델이 어떤 데이터를 기반으로 예측을 수행하는지를 빠르게 확인할 수 있는 좋은 예시입니다. 피처(특징)들이 어떻게 영향을 주는지도 Rank 위젯을 통해 시각적으로 확인해보세요!
🧠 실습 2: 딥러닝 모델 만들어 보기
- 동일한 Iris 데이터셋을 File 위젯으로 불러옵니다.
- Neural Network 위젯을 연결해 딥러닝 모델을 생성합니다.
- 은닉층 수나 뉴런 수를 조절해가며 성능 변화를 관찰해보세요.
- 다시 Test & Score를 연결해서 머신러닝 모델과 비교해보세요!
놀랍게도, 단순한 데이터셋에서는 머신러닝과 딥러닝 모두 비슷한 성능을 낼 수 있어요. 하지만 더 복잡한 이미지, 음성, 텍스트로 가면 딥러닝의 성능이 확연히 앞서죠.
💡 팁: 모델 비교 실험 정리해보기
| 항목 | 머신러닝 | 딥러닝 |
|---|---|---|
| Orange 사용 위젯 | Tree, Logistic Regression | Neural Network |
| 튜닝 요소 | 알고리즘 선택, 테스트 전략 | 층 수, 뉴런 수, 활성 함수 |
| 시각화 | Scatter Plot, Confusion Matrix | Confusion Matrix, ROC Curve |
이처럼 같은 데이터, 다른 접근을 통해 머신러닝과 딥러닝의 차이를 직접 체감할 수 있어요. 특히 Orange는 시각적으로 모든 과정을 보여주기 때문에 처음 딥러닝을 배우는 분들도 거부감 없이 실습할 수 있는 최고의 도구입니다!
6. 언제 무엇을 선택할까?
이제 질문 하나 드릴게요. 여러분이 데이터 분석 프로젝트를 시작했어요. 과연 머신러닝을 써야 할까요, 딥러닝을 써야 할까요? 이건 생각보다 간단한 문제는 아니에요. 하지만 기준은 분명히 있어요!
🔑 선택 기준 체크리스트
- 데이터 크기: 수천 건 정도면 머신러닝, 수십만 건 이상이면 딥러닝
- 데이터 형태: 숫자, 범주형 데이터 = 머신러닝 / 이미지, 음성, 텍스트 = 딥러닝
- 해결 난이도: 단순 예측 문제 = 머신러닝 / 복잡한 패턴 인식 = 딥러닝
- 학습 리소스: 자원이 적고 빠른 결과가 필요하다면 머신러닝
💬 실제 상황에 적용해보기
- 고객 이탈 예측: 고객 데이터가 수천 건이고, 범주형/수치형 데이터 위주라면 머신러닝이 효율적이에요. - 사진 속 사람 얼굴 인식: 픽셀로 이루어진 이미지 데이터를 처리해야 하므로, 딥러닝이 적합해요. - 문서 분류나 감성 분석: 텍스트 데이터의 맥락을 파악해야 하므로 딥러닝 기반의 자연어 처리 모델이 유리해요.
🧡 Orange 활용 Tip
- 먼저 간단한 머신러닝 모델을 시도해보고, 성능이 한계에 부딪히면 딥러닝으로 넘어가는 전략이 좋아요!
- Orange의 시각화 기능을 적극 활용해서 각 모델의 성능 차이를 비교해보세요.
결론적으로 중요한 건, 내가 가진 문제에 딱 맞는 도구를 쓰는 것이에요. 딥러닝이 무조건 최고? 아니죠. 머신러닝도 여전히 실무에서 많이 쓰이는 이유가 있습니다.
기술은 결국, 문제 해결을 위한 수단이라는 걸 잊지 마세요!
📌 마무리하며: 딥러닝과 머신러닝, 무엇이든 적재적소에!
지금까지 딥러닝(Deep Learning)과 전통적인 머신러닝(Machine Learning)의 차이를 이론, 비교표, 실생활 사례, 그리고 Orange 실습까지 통해 상세히 알아봤습니다. 딥러닝은 자동화된 특징 학습과 복잡한 패턴 인식에 강점이 있는 반면, 머신러닝은 빠르고 직관적인 모델링에 유리하다는 점이 주요 차이였죠.
실제 프로젝트에서는 이 두 기술을 혼합하거나 단계별로 적용하는 경우도 많아요. 예를 들어 초기 탐색에는 머신러닝을, 정교한 예측 모델링에는 딥러닝을 사용하는 식이죠. 무엇보다 중요한 건, 데이터의 특성과 문제의 복잡도에 맞는 선택입니다.
앞으로 여러분이 AI와 데이터 분석을 활용하는 실무 또는 프로젝트에서 머신러닝과 딥러닝 중 어떤 걸 쓸지 고민될 때, 오늘 정리한 내용을 떠올리며 현명한 선택을 하시길 바랍니다 😊 Orange 같은 도구를 통해 직접 실험하면서 자신만의 인사이트를 쌓는 것도 정말 좋은 방법이에요!
이해가 안 갔던 용어나 개념이 조금 더 선명해졌다면, 그걸로 이 글은 성공입니다. 이제 다음 단계로, 인공신경망 구조와 뉴런의 작동 방식에 대해 같이 알아보러 가볼까요? 🧠
'OrangeDataMining' 카테고리의 다른 글
| 뉴런과 활성 함수(Sigmoid, ReLU, Tanh, Softmax) (0) | 2025.05.01 |
|---|---|
| 인공신경망(Artificial Neural Networks, ANN) 구조 완전 정복 (1) | 2025.05.01 |
| 딥 Q-네트워크(DQN) 개요 및 실무 적용 사례 (1) | 2025.04.30 |
| Q-Learning 개념 및 기본 원리 완전 정복 (0) | 2025.04.30 |
| 탐색과 활용의 균형(Exploration vs Exploitation) 완전정복 (3) | 2025.04.30 |



